Vitis AI is AMD’s framework for accelerating AI inference on programmable SoC devices. Vitis AI takes a pre-trained neural network, described in PyTorch or TensorFlow, and generates a deep learning processor unit, a logic core that can run inference on the neural network in real time.
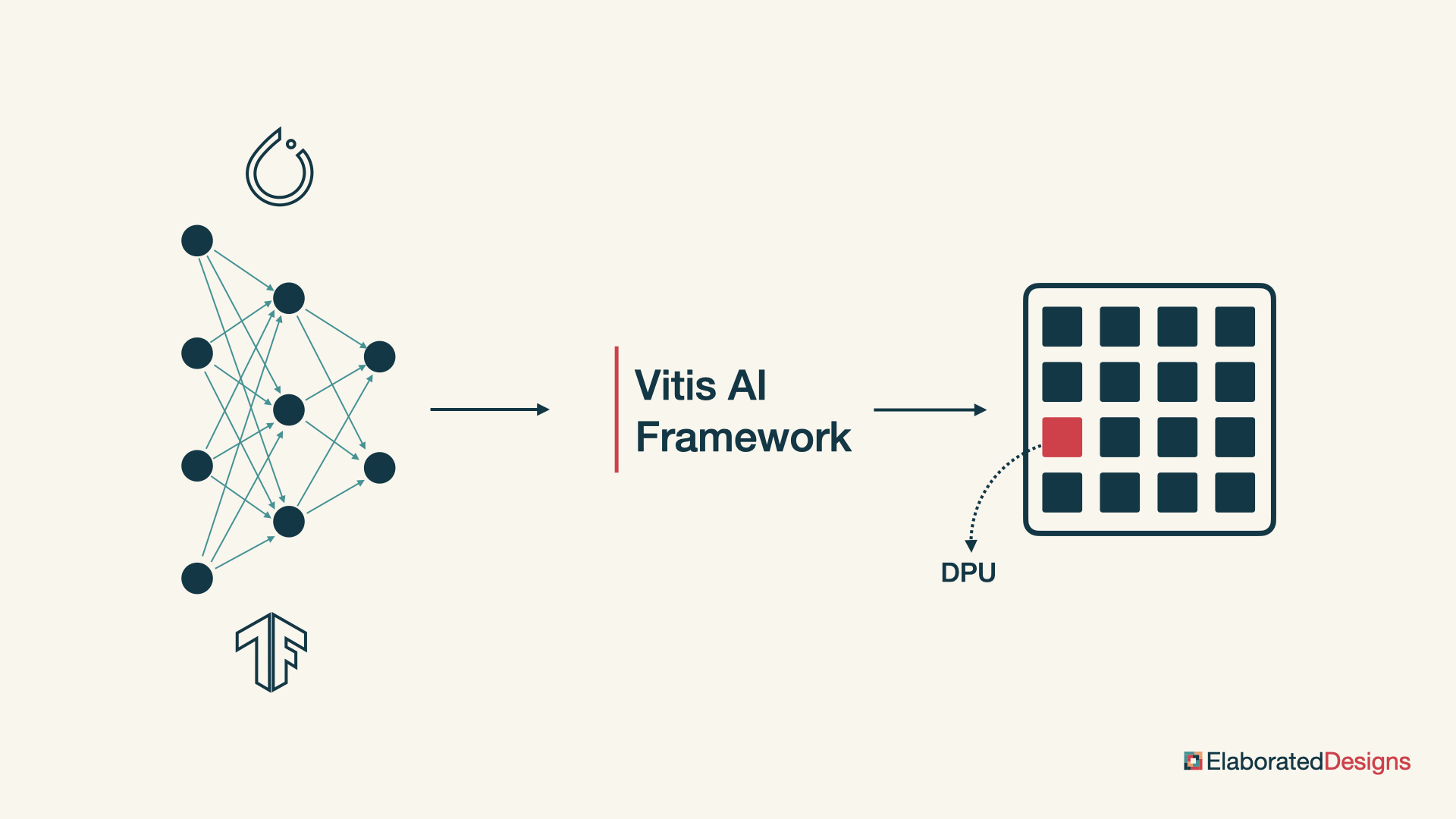
We can think of Vitis AI as having three major components: the deep learning processor unit, model development tools to compile and optimize neural network models for the deep learning processor unit, and model deployment libraries and APIs to execute the neural network models on the deep learning processor unit from a software application.
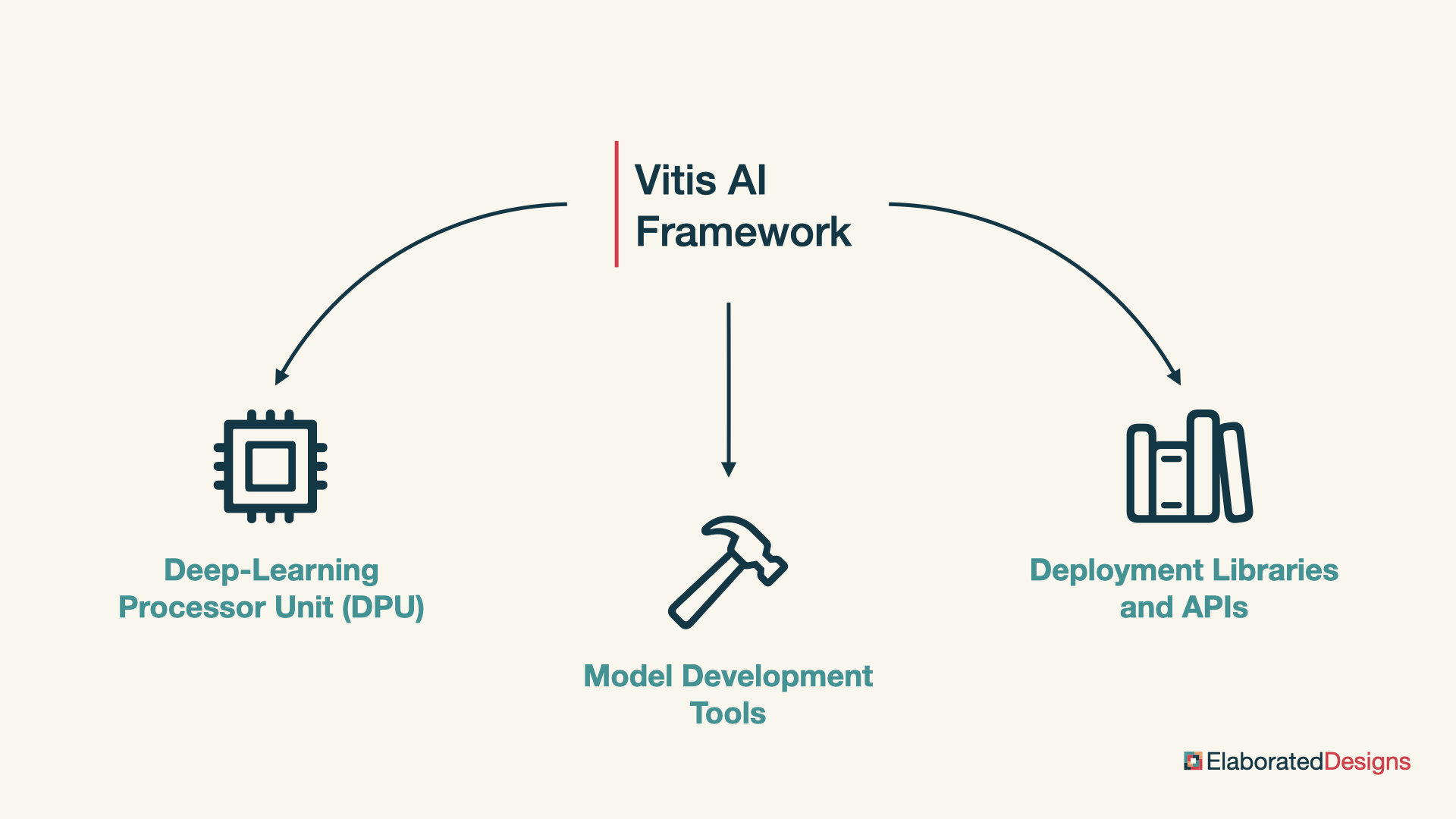
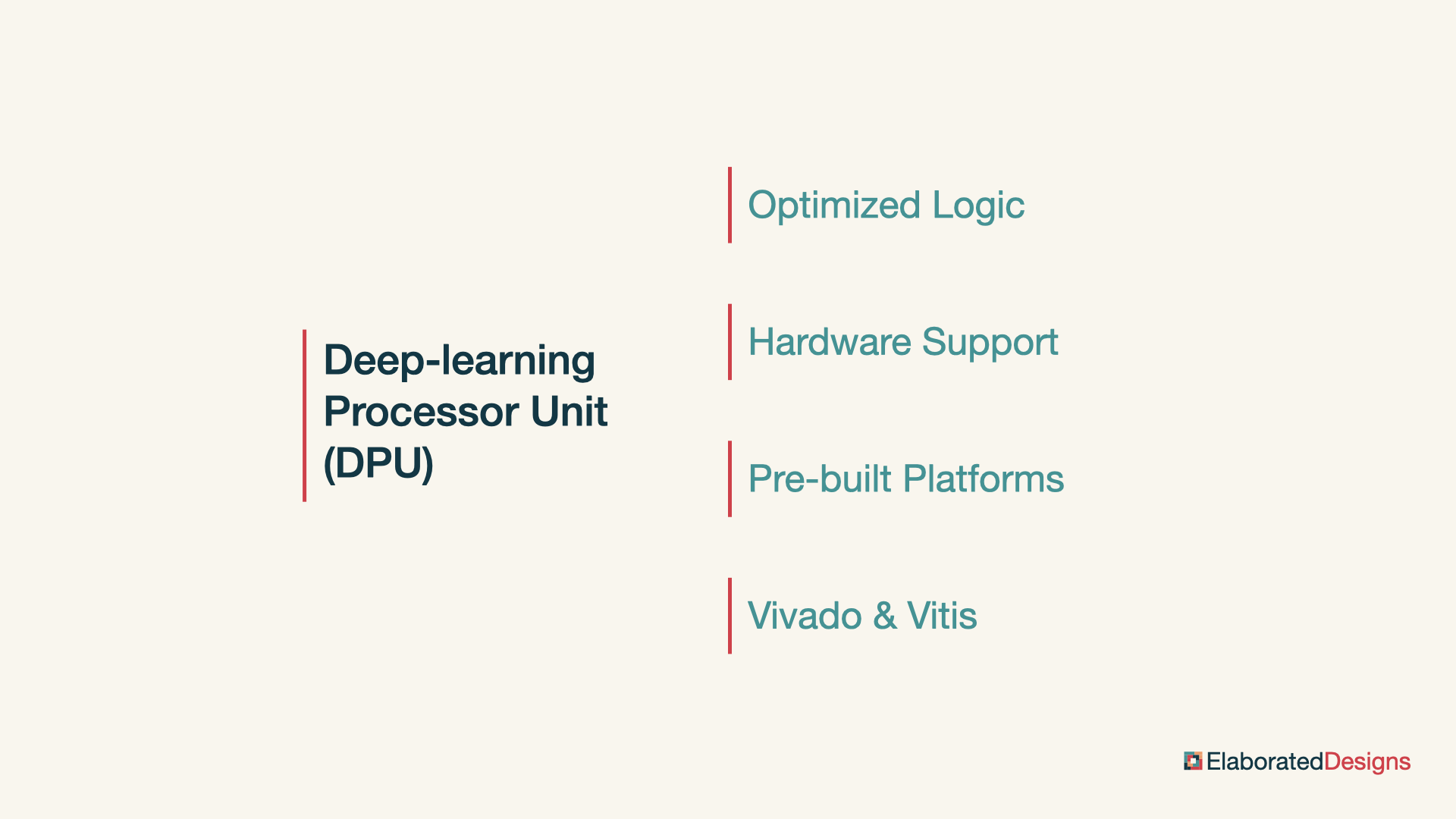
Deep-learning Processor Unit
The deep learning processor unit, or DPU, is a programmable engine optimized for deep neural networks. It implements a tensor-level instruction set designed to support and accelerate various popular convolutional neural networks.
The DPU can run on Zynq ultrascale plus, Kria, Versal and Alveo platforms. AMD provides pre-built platforms that include the DPU for different use cases, supporting programming and deployment by non-FPGA experts.
In embedded applications, the DPU can be integrated in a custom design along with other functionality in the programmable logic, following the traditional development flow with Vivado and Vitis.
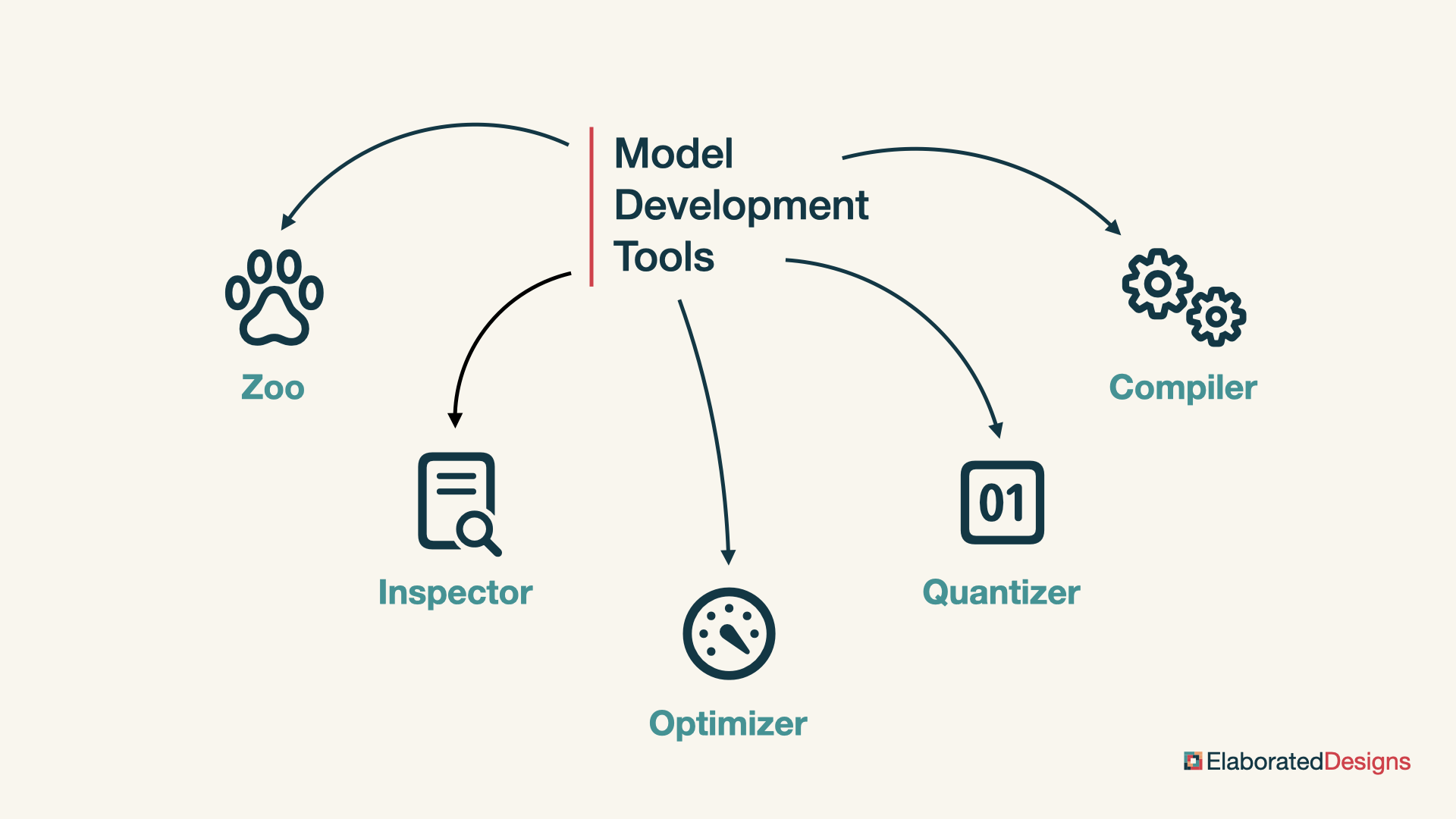
Model Development
There are five tools that facilitate the development of inference models targeting the DPU: the model zoo, the inspector, the optimizer, the quantizer and the compiler.
Model Zoo
The Vitis AI Model Zoo includes pre-optimized models to help speed up deployment to the DPU. These are based on popular deep learning neural networks that cover several common applications in video processing, assisted driving and robotics.
Inspector
The Vitis AI model Inspector performs initial sanity checks to confirm that the operators and sequence of operations in the neural network are compatible with Vitis AI. This helps predict how much effort will be required to achieve our desired performance for a specific model, if it will be possible at all.
Optimizer
The Vitis AI Optimizer reduces the computational complexity of the model by eliminating the operations that contribute little to the overall performance of the neural network. This results in a potentially much smaller model and quicker inference, at the cost of minimal performance degradation.
Quantizer
The Vitis AI Quantizer converts the 32-bit floating point parameters of the neural network to fixed-point integers. The fixed-point parameters require less memory and bandwidth, and the fixed-point operations are faster and consume less energy than their floating-point equivalents.
Compiler
Finally, the Vitis AI Compiler maps the quantized model to an instruction set and dataflow model that takes advantage of the DPU architecture.
Model Deployment
The Vitis AI Framework includes three components to help us deploy our model: the Vitis AI Runtime, the Vitis AI Library, and the Vitis AI Profiler.
Runtime
The Vitis AI Runtime is a set of low-level API functions that support the integration of the DPU into software applications. The Vitis AI Runtime is built on top of the Xilinx Runtime, which is also used by the Vitis Acceleration framework, supports asynchronous submission and collection of jobs from the DPU, and includes C++ and Python API implementations.
Library
The Vitis AI Library is a set of high-level libraries and APIs built on top of the Vitis AI Runtime. These high-level libraries include common operations for preprocessing, inference, and postprocessing that can be more quickly integrated into our application than if we were to implement everything from scratch.
Profiler
Finally, the Vitis AI Profiler analyzes our AI application and provides visualizations to help us identify bottlenecks and allocate computational resources more efficiently. The Vitis AI Profiler can trace function calls and collect hardware information, including CPU, DPU, and memory utilization.
Summary
In summary, Vitis AI is AMD’s framework for accelerating AI inference on programmable SoC devices. It has three major components: the deep learning processor unit, model development tools, and model deployment libraries and APIs. The DPU is a programmable engine optimized for running inference with deep neural networks on AMD devices. The model development tools include the model zoo, the model inspector, the optimizer, the quantizer and the compiler. Lastly, the model deployment tools include the Vitis AI runtime, library, and profiler.

Cheers,
Isaac